

Q: – What is Machine learning?
Ans:- Machine learning is a branch of computer science which deals with system programming in order to automatically learn and improve with experience.
For example: Robots are programmed so that they can perform the task based on data they gather from sensors. It automatically learns programs from data.
OR
Machine learning is the field of study that gives the computer the ability to learn and improve from experience without explicitly taught or programmed.In traditional programs, the rules are coded for a program to make decisions, but in machine learning, the program learns based on the data to make decisions.
Q: – What do you understand by Machine Learning?
Ans:- Machine learning is an application of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed.
Machine learning focuses on the development of computer programs that can access data and use it learn for themselves.
Q: – What are Different types of learning in machine learning ?
Ans:-
Supervised learning
Unsupervised learning
Reinforcement learning
Semi supervised learning
Q: – What is the difference between supervised and unsupervised machine learning?
Ans:- By definition, the supervised and unsupervised learning algorithms are categorized based on the supervision required while training. Supervised learning algorithms work on data which are labelled i.e. the data has a desired solution or a label. On the other hand, unsupervised learning algorithms work on unlabeled data, meaning that the data does not contain the desired solution for the algorithm to learn from.
Variance is error due to too much complexity in the learning algorithm you’re using. This leads to the algorithm being highly sensitive to high degrees of variation in your training data, which can lead your model to overfit the data. You’ll be carrying too much noise from your training data for your model to be very useful for your test data.
The bias-variance decomposition essentially decomposes the learning error from any algorithm by adding the bias, the variance and a bit of irreducible error due to noise in the underlying dataset.
Essentially, if you make the model more complex and add more variables, you’ll lose bias but gain some variance — in order to get the optimally reduced amount of error, you’ll have to tradeoff bias and variance.
You don’t want either high bias or high variance in your model.
Supervised algorithm examples:
- Linear Regression
- Logistic Regression
- Random Forest
- Naive bayes
- Neural Networks/Deep Learning
- Decision Trees
- Support Vector Machine (SVM)
- K-Nearest neighbours (KNN)
- Classifications
- Speech recognition
- Regression
- Predict time series
- Annotate strings
Unsupervised algorithm examples:
- Clustering Algorithms – K-means, Hierarchical Clustering Analysis (HCA)
- Visualization and Dimensionality reduction – Principal component reduction (PCA)
- Association rule learning
- Find clusters of the data of the data
- Find low-dimensional representations of the data
- Find interesting directions in data
- Interesting coordinates and correlations
- Find novel observations
- K-means
- t-SNE Clustering
- DBSCAN Clustering
- Anomaly detection
Q: – Is recommendation supervised or unsupervised learning?
Ans:-
Recommendation algorithms are interesting as some of these are supervised and some are unsupervised. The recommendations based on your profile, previous purchases, page views fall under supervised learning. But there are recommendations based on hot selling products, country/location-based recommendations, which are unsupervised learning.
Q: – What is Reinforcement learning ?
Ans:- Reinforcement learning is an important type of Machine Learning where an agent learn how to behave in a environment by performing actions and seeing the results.
Q: – What are best algorithms for Reinforcement learning ?
Ans:- Q-Learning
Q: – Define what is Fourier Transform in a single sentence?
Ans:- A process of decomposing generic functions into a superposition of symmetric functions is considered to be a Fourier Transform.
Q: – What is deep learning?
Ans:- Deep learning is a process where it is considered to be a subset of machine learning process.
Q: – What is the F1 score?
Ans:- The F1 score is defined as a measure of a model’s performance
Q: – How is F1 score is used?
Ans:- The average of Precision and Recall of a model is nothing but F1 score measure. Based on the results, the F1 score is 1 then it is classified as best and 0 being the worst.
Ans:-
Recommendation algorithms are interesting as some of these are supervised and some are unsupervised. The recommendations based on your profile, previous purchases, page views fall under supervised learning. But there are recommendations based on hot selling products, country/location-based recommendations, which are unsupervised learning.
Q: – What is Reinforcement learning ?
Ans:- Reinforcement learning is an important type of Machine Learning where an agent learn how to behave in a environment by performing actions and seeing the results.
Q: – What are best algorithms for Reinforcement learning ?
Ans:- Q-Learning
Q: – Define what is Fourier Transform in a single sentence?
Ans:- A process of decomposing generic functions into a superposition of symmetric functions is considered to be a Fourier Transform.
Q: – What is deep learning?
Ans:- Deep learning is a process where it is considered to be a subset of machine learning process.
Q: – What is the F1 score?
Ans:- The F1 score is defined as a measure of a model’s performance
Q: – How is F1 score is used?
Ans:- The average of Precision and Recall of a model is nothing but F1 score measure. Based on the results, the F1 score is 1 then it is classified as best and 0 being the worst.
Q: – How can you ensure that you are not overfitting with a particular model?
Ans:- In Machine Learning concepts, they are three main methods or processes to avoid overfitting:
Firstly, keep the model simple
Must and should use cross validation techniques
It is mandatory to use regularization techniques, for example, LASSO.
Q: – What is the difference between Type I and Type II error?
Ans:- Type I error is false positive, while Type II is false negative. Type I error is claiming something has happened when it hasn’t. For instance, telling a man he is pregnant. On the other hand, Type II error means you claim nothing is happened but in fact something is. To exemplify, you tell a pregnant lady she isn’t carrying baby.
Q: – You are given a data set. The data set has missing values which spread along 1 standard deviation from the median. What percentage of data would remain unaffected? Why?
Ans:- This question has enough hints for you to start thinking! Since, the data is spread across median, let’s assume it’s a normal distribution. We know, in a normal distribution, ~68% of the data lies in 1 standard deviation from mean (or mode, median), which leaves ~32% of the data unaffected. Therefore, ~32% of the data would remain unaffected by missing values.
Q: – Why overfitting happens?
Ans:-The possibility of overfitting exists as the criteria used for training the model is not the same as the criteria used to judge the efficacy of a model.
Q: – Explain what is precision and Recall?
Ans:- Recall:
It is known as a true positive rate. The number of positives that your model has claimed compared to the actual defined number of positives available throughout the data.
Precision:
It is also known as a positive predicted value. This is more based on the prediction. It is a measure of a number of accurate positives that the model claims when compared to the number of positives it actually claims.
Q: – Why do ensembles typically have higher scores than individual models?
Ans:- An ensemble is the combination of multiple models to create a single prediction. The key idea for making better predictions is that the models should make different errors. That way the errors of one model will be compensated by the right guesses of the other models and thus the score of the ensemble will be higher
We need diverse models for creating an ensemble. Diversity can be achieved by:
Using different ML algorithms. For example, you can combine logistic regression, k-nearest neighbors, and decision trees.
Using different subsets of the data for training. This is called bagging.
Giving a different weight to each of the samples of the training set. If this is done iteratively, weighting the samples according to the errors of the ensemble, it’s called boosting
.
Many winning solutions to data science competitions are ensembles. However, in real-life machine learning projects, engineers need to find a balance between execution time and accuracy
Q: – What is Supervised learning?
Ans:- When the data is labeled in during training process it’s calling supervised learning
Q: – What is Unsupervised learning?
Ans:- When the data is not labeled in during training process it’s calling supervised learning
Q: –What’s the trade-off between bias and variance?
Ans:-
Bias is error due to over simplistic assumptions in the learning algorithm that you are using, which can lead to model under fitting your data and making it hard for model to give accurate predictions.
Variance, on the other hand, is error due to way too much complexity in your learning algorithm. Due to this complexity, the algorithm is highly sensitive to high degrees of variation, which can lead your model to over fit the data. In addition, you will be carrying too much noise from your training data for your model to be useful.
The bias-variance decomposition essentially decomposes the learning error from any algorithm by adding the bias, the variance and a bit of irreducible error due to noise in the underlying data-set. Essentially, if you make the model more complex and add more variables, you’ll lose bias but gain some variance — in order to get the optimally reduced amount of error, you’ll have to trade-off bias and variance. You don’t want either high bias or high variance in your model.
Q: – What is Bayes’ Theorem? How is it useful in a machine learning context?
Ans:- Bayes’ Theorem gives you the posterior probability of an event given what is known as prior knowledge.
Mathematically, it’s expressed as the true positive rate of a condition sample divided by the sum of the false positive rate of the population and the true positive rate of a condition. Say you had a 60% chance of actually having the flu after a flu test, but out of people who had the flu, the test will be false 50% of the time, and the overall population only has a 5% chance of having the flu. Would you actually have a 60% chance of having the flu after having a positive test?
Bayes’ Theorem says no. It says that you have a (.6 * 0.05) (True Positive Rate of a Condition Sample) / (.6*0.05)(True Positive Rate of a Condition Sample) + (.5*0.95) (False Positive Rate of a Population) = 0.0594 or 5.94% chance of getting a flu.

Q: – What are the basic differences between Machine Learning and Deep Learning?
Ans:-
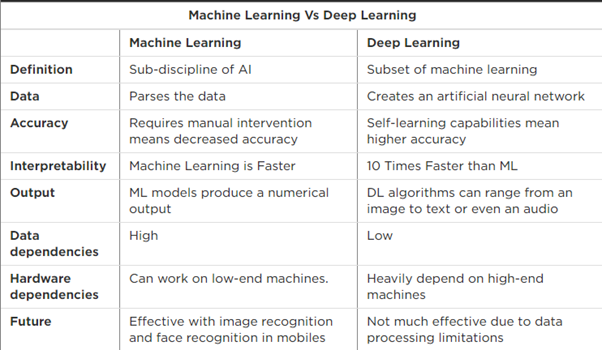
OR
Q: – You are given a train data set having 1000 columns and 1 million rows. The data set is based on a classification problem. Your manager has asked you to reduce the dimension of this data so that model computation time can be reduced. Your machine has memory constraints. What would you do? (You are free to make practical assumptions.)
Ans:- Processing a high dimensional data on a limited memory machine is a strenuous task, your interviewer would be fully aware of that. Following are the methods you can use to tackle such situation:
Since we have lower RAM, we should close all other applications in our machine, including the web browser, so that most of the memory can be put to use.
We can randomly sample the data set. This means, we can create a smaller data set, let’s say, having 1000 variables and 300000 rows and do the computations.
To reduce dimensionality, we can separate the numerical and categorical variables and remove the correlated variables. For numerical variables, we’ll use correlation. For categorical variables, we’ll use chi-square test.
Also, we can use PCA and pick the components which can explain the maximum variance in the data set.
Using online learning algorithms like Vowpal Wabbit (available in Python) is a possible option.
Building a linear model using Stochastic Gradient Descent is also helpful.
We can also apply our business understanding to estimate which all predictors can impact the response variable. But, this is an intuitive approach, failing to identify useful predictors might result in significant loss of information.
Q: – mention the difference between Data Mining and Machine learning?
Ans:- Machine learning relates with the study, design and development of the algorithms that give computers the capability to learn without being explicitly programmed. While, data mining can be defined as the process in which the unstructured data tries to extract knowledge or unknown interesting patterns. During this process machine, learning algorithms are used.
Q: – How is KNN different from k-means clustering?
Ans:- K-Nearest Neighbors is a supervised classification algorithm, while k-means clustering is an unsupervised clustering algorithm. While the mechanisms may seem similar at first, what this really means is that in order for K-Nearest Neighbors to work, you need labeled data you want to classify an unlabeled point into (thus the nearest neighbor part). K-means clustering requires only a set of unlabeled points and a threshold: the algorithm will take unlabeled points and gradually learn how to cluster them into groups by computing the mean of the distance between different points.
The critical difference here is that KNN needs labeled points and is thus supervised learning, while k-means doesn’t — and is thus unsupervised learning.
OR
The crucial difference between both is, K-Nearest Neighbor is a supervised classification algorithm, whereas k-means is an unsupervised clustering algorithm. While the procedure may seem similar at first, what it really means is that in order to K-Nearest Neighbors to work, you need labelled data which you want to classify an unlabeled point into. In k-means clustering it requires set of unlabeled points and a threshold only. The algorithm will take that unlabeled data and will learn how to cluster them into groups by computing the mean of the distance between different points.Q: –Give an example that explains Machine Learning in industry.
Ans:- Robots are replacing humans in many areas. It is because robots are programmed such that they can perform the task based on data they gather from sensors. They learn from the data and behaves intelligently.
Q: – Is rotation necessary in PCA? If yes, Why? What will happen if you don’t rotate the components?
Ans:- Yes, rotation (orthogonal) is necessary because it maximizes the difference between variance captured by the component. This makes the components easier to interpret. Not to forget, that’s the motive of doing PCA where, we aim to select fewer components (than features) which can explain the maximum variance in the data set. By doing rotation, the relative location of the components doesn’t change, it only changes the actual coordinates of the points.
If we don’t rotate the components, the effect of PCA will diminish and we’ll have to select more number of components to explain variance in the data set.
Q: – What is ‘Overfitting’ in Machine learning?
Ans:- In machine learning, when a statistical model describes random error or noise instead of underlying relationship ‘overfitting’ occurs. When a model is excessively complex, overfitting is normally observed, because of having too many parameters with respect to the number of training data types. The model exhibits poor performance which has been overfit.
Q: – What is the difference between Bias and Variance?
Ans:-
Bias:Bias can be defined as a situation where an error has occurred due to use of assumptions in the learning algorithm.
Variance:Variance is an error caused because of the complexity of the algorithm that is been used to analyze the data.
Q: – What is stratified cross-validation and when should we use it?
Ans:-
cross-validation is a technique for dividing data between training and validation sets. On typical cross-validation this split is done randomly. But in stratified cross-validation, the split preserves the ratio of the categories on both the training and validation datasets.
For example, if we have a dataset with 10% of category A and 90% of category B, and we use stratified cross-validation, we will have the same proportions in training and validation. In contrast, if we use simple cross-validation, in the worst case we may find that there are no samples of category A in the validation set. Stratified cross-validation may be applied in the following scenarios:
- On a dataset with multiple categories. The smaller the dataset and the more imbalanced the categories, the more important it will be to use stratified cross-validation.
- On a dataset with data of different distributions. For example, in a dataset for autonomous driving, we may have images taken during the day and at night. If we do not ensure that both types are present in training and validation, we will have generalization problems.
Ans:-
• Reinforcement Learning
• Supervised Learning
• Unsupervised Learning
• Semi-supervised Learning
• Transduction
• Learning to Learn
Q: – Why is naive Bayes so naive?
Ans:- Naive Bayes is so naive because it assumes that all of the features in a dataset are equally important and independent.
Q: – What is Semi supervised learning ?
Ans:- Semi-supervised learning is a class of machine learning tasks and techniques that also make use of unlabeled data for training – typically a small amount of labeled data with a large amount of unlabeled data. Semi-supervised learning falls between unsupervised learning and supervised learning
Q: – You are given a data set on cancer detection. You’ve build a classification model and achieved an accuracy of 96%. Why shouldn’t you be happy with your model performance? What can you do about it?
Ans:- If you have worked on enough data sets, you should deduce that cancer detection results in imbalanced data. In an imbalanced data set, accuracy should not be used as a measure of performance because 96% (as given) might only be predicting majority class correctly, but our class of interest is minority class (4%) which is the people who actually got diagnosed with cancer.
Hence, in order to evaluate model performance, we should use Sensitivity (True Positive Rate), Specificity (True Negative Rate), F measure to determine class wise performance of the classifier.
If the minority class performance is found to to be poor, we can undertake the following steps:
- We can use undersampling, oversampling or SMOTE to make the data balanced.
- We can alter the prediction threshold value by doing probability caliberation and finding a optimal threshold using AUC-ROC curve.
- We can assign weight to classes such that the minority classes gets larger weight.
- We can also use anomaly detection.
Ans:- By using a lot of data overfitting can be avoided, overfitting happens relatively as you have a small dataset, and you try to learn from it. But if you have a small database and you are forced to come with a model based on that. In such situation, you can use a technique known as cross validation. In this method the dataset splits into two section, testing and training datasets, the testing dataset will only test the model while, in training dataset, the datapoints will come up with the model.
In this technique, a model is usually given a dataset of a known data on which training (training data set) is run and a dataset of unknown data against which the model is tested. The idea of cross validation is to define a dataset to “test” the model in the training phase.
Q: –What Deep Learning is exactly?
Ans:- Most people don’t know this but Machine Learning and Deep Learning is not two different things, but Deep learning is a subset of Machine learning. It mostly deals with neural networks: how to use back propagation and other certain principles from neuroscience to more accurately model large sets of unlabeled data. In a nutshell, Deep Learning represents unsupervised learning algorithm that learns data representation mainly through neural networks. Explore a little about neural nets to answer deep learning interview questions effectively.
Q: – What’s the difference between a generative and discriminative model?
Ans:- A discriminating model will learn the distinction between different categories of data, while A generative model will learn categories of data. Discriminative models will predominantly outperform generative models on classification tasks.
Q: – What is your favorite algorithm and also explain the algorithm in briefly in a minute?
Ans:- This type of questions is very common and asked by the interviewers to understand the candidate skills and assess how well he can communicate complex theories in the simplest language.
This one is a tough question and usually, individuals are not at all prepared for this situation so please be prepared and have a choice of algorithms and make sure you practice a lot before going into any sort of interviews.
Q: – What is the difference between Type 1 and Type 2 errors?
Ans:-
Type 1 error is classified as a false positive. I.e. This error claims that something has happened but the fact is nothing has happened. It is like a false fire alarm. The alarm rings but there is no fire.
Type 2 error is classified as a false negative. I.e. This error claims that nothing has happened but the fact is that actually, something happened at the instance.
The best way to differentiate a type 1 vs type 2 error is:
Calling a man to be pregnant- This is Type 1 example
Calling pregnant women and telling that she isn’t carrying any baby- This is type 2 example
Q: – What are the advantages of Naive Bayes?
Ans:- The advantages of Naive Bayes are:
The classifier will converge quicker than discriminative models
It cannot learn the interactions between features
Let us move to the next Machine Learning Interview Questions.
Q: – What are the disadvantages of Naive Bayes?
Ans:- The disadvantages of Naive Bayes are:
It is because the problem arises for continuous features
It makes a very strong assumption on the shape of your data distribution.
It can also happen because of data scarcity
Q: – What is Anomaly detection ?
Ans:- Anomaly detection is the identification of data points, items, observations or events that do not conform to the expected pattern of a given group. These anomalies occur very infrequently but may signify a large and significant threat such as cyber intrusions or fraud.
Q: – What is Bias, Variance and Trade-off ?
Ans:- Bias is the simplifying assumptions made by the model to make the target function easier to approximate. Variance is the amount that the estimate of the target function will change given different training data. Trade-off is tension between the error introduced by the bias and the variance.
Q: – What is Overfitting in Machine Learning?
Ans:- This is the popular Machine Learning Interview Questions asked in an interview. Overfitting in Machine Learning is defined as when a statistical model describes random error or noise instead of the underlying relationship or when a model is excessively complex.
Q: –What are the conditions when Overfitting happens?
Ans:- One of the important reason and possibility of overfitting is because the criteria used for training the model is not the same as the criteria used to judge the efficacy of a model.
Q: – How can you avoid overfitting?
Ans:- We can avoid overfitting by using:
• Lots of data
• Cross-validation
Q: – What are the five popular algorithms for Machine Learning?
Ans:- Below is the list of five popular algorithms of Machine Learning:
• Decision Trees
• Probabilistic networks
• Nearest Neighbor
• Support vector machines
• Neural Networks
Q: – What are the different use cases where machine learning algorithms can be used?
Ans:-
The different use cases where machine learning algorithms can be used are as follows:
• Fraud Detection
• Face detection
• Natural language processing
• Market Segmentation
• Text Categorization
• Bioinformatics
Q: –What are parametric models and Non-Parametric models?
Ans:-
Parametric models are those with a finite number of parameters and to predict new data, you only need to know the parameters of the model.
Non Parametric models are those with an unbounded number of parameters, allowing for more flexibility and to predict new data, you need to know the parameters of the model and the state of the data that has been observed.
Q: – Explain what is the function of ‘Supervised Learning’?
Ans:-
a) Classifications
b) Speech recognition
Q: – What are the three stages to build the hypotheses or model in machine learning?
Ans:-
This is the frequently asked Machine Learning Interview Questions in an interview. The three stages to build the hypotheses or model in machine learning are:
1. Model building
2. Model testing
3. Applying the model
Q: – What is not Machine Learning?
Ans:-
a) Artificial Intelligence
b) Rule based inference
Q: – What is classification ? When we will use this method ?
Ans:- In machine learning and statistics, classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known.
Q: – What is clustering ? When we will use this method ?
Ans:- Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups
Q: – What is regularization ?
Ans:- This is a form of regression, that constrains/ regularizes or shrinks the coefficient estimates towards zero. In other words, this technique discourages learning a more complex or flexible model, so as to avoid the risk of overfitting.
Q: – What is Difference between l1 regularization and l2 regularization ?
Ans:- Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. The difference between the L1and L2 is just that L2 is the sum of the square of the weights, while L1 is just the sum of the weights
Q: – What ensemble learning ?
Ans:- Ensemble learning is the process by which multiple models, such as classifiers or experts, are strategically generated and combined to solve a particular computational intelligence problem.
Q: – Why is naive Bayes so ‘naive’ ?
Ans:- naive Bayes is so ‘naive’ because it assumes that all of the features in a data set are equally important and independent. As we know, these assumption are rarely true in real world scenario.
Q: – Explain prior probability, likelihood and marginal likelihood in context of naiveBayes algorithm?
Ans:- Prior probability is nothing but, the proportion of dependent (binary) variable in the data set. It is the closest guess you can make about a class, without any further information. For example: In a data set, the dependent variable is binary (1 and 0). The proportion of 1 (spam) is 70% and 0 (not spam) is 30%. Hence, we can estimate that there are 70% chances that any new email would be classified as spam.
Likelihood is the probability of classifying a given observation as 1 in presence of some other variable. For example: The probability that the word ‘FREE’ is used in previous spam message is likelihood. Marginal likelihood is, the probability that the word ‘FREE’ is used in any message.
Q: – How is True Positive Rate and Recall related? Write the equation.
Ans:- True Positive Rate = Recall. Yes, they are equal having the formula (TP/TP + FN).
Q: – What is inductive machine learning?
Ans:- The inductive machine learning involves the process of learning by examples, where a system, from a set of observed instances tries to induce a general rule.
Q: – What are the five popular algorithms of Machine Learning?
Ans:-
Decision Trees
Neural Networks (back propagation)
Probabilistic networks
Nearest Neighbor
Support vector machines
-----------------------------------------------------------------------------
Thanks for Watching...
Please "SUBSCRIBE!" to Cloud Network Channel and Share my Channel and Videos to Friends/Relatives.
Suggest me How can i growth my channel views, videos, content, likes, subscriber .
Let me know
What can i video make and upload to viewers and anyone want to join or help they are free to join email me on itcloudnet@gmail.com for more discussion.

