Q: – What is AWS ?
Ans:-
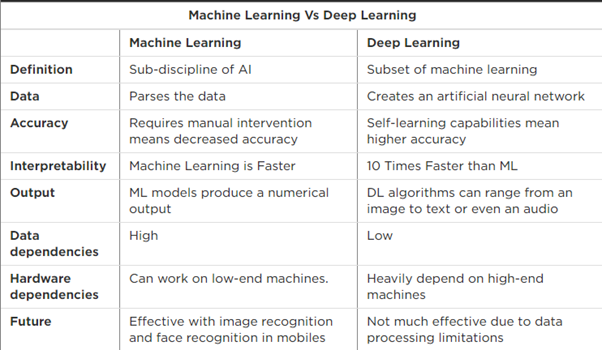
AWS (Amazon Web Services) is a platform to provide secure cloud services, database storage, offerings to compute power, content delivery, and other services to help business level and develop.
OR
AWS stands for Amazon Web Services. AWS is a platform that provides on-demand resources for hosting web services, storage, networking, databases and other resources over the internet with a pay-as-you-go pricing.
OR
AWS stands for Amazon Web Service; it is a collection of remote computing services also known as a cloud computing platform. This new realm of cloud computing is also known as IaaS or Infrastructure as a Service.
OR
It is the acronym for Amazon Web Service. It is a comprehensive, evolving cloud-computing platform of Amazon. It is also known as Infrastructure as a Service (IaaS).
Q: – What is AWS ?
OR
This is one of the most basic AWS interview questions and can be answered in both simple and complex structures, depending on the interviewer.
According to the terminology, AWS or Amazon Web Services is defined as a platform which is designed to provide secure cloud services, computing power to clients, database storage options, content delivery and many other services which are all intended towards business development and growth.
OR
AWS stands for Amazon Web Services and is a platform that provides database storage, secure cloud services, offering to compute power, content delivery, and many other services to develop business levels.
Q: – What is the importance of buffer in Amazon Web Services?
Ans:- An Elastic Load Balancer ensures that the incoming traffic is distributed optimally across various AWS instances. A buffer will synchronize different components and makes the arrangement additional elastic to a burst of load or traffic. The components are prone to work in an unstable way of receiving and processing the requests.
The buffer creates the equilibrium linking various apparatus and crafts them effort at the identical rate to supply more rapid services.
Q: – What do you know about Buffer in AWS?
Ans:- A buffer is necessary in any cloud computing technology in order to maintain seamless integration across a huge flow of traffic and loads. The Elastic Load Balancer in Amazon Web Services has been designed in a way to ensure that all the incoming traffic is optimally distributed across all channels of AWS instances.
The presence of a buffer enables the components to work in an unstable situation and receive and process requests as it gets them. Essentially the presence of a buffer is needed to create an equilibrium between all the apparatus and provide them with an identical ability to supply more rapid services
Q: – How is buffer used in AWS?
Ans:-It is used to make the system more robust and manage traffic by synchronizing different components.The component processes the requests in an imbalanced way.Using buffer, the components work at the same speed for faster services and will also be balanced.
Q: – What are the components of AWS?
Ans:- EC2 – Elastic Compute Cloud, S3 – Simple Storage Service, Route53, EBS – Elastic Block Store, Cloudwatch, Key-Paris are few of the components of AWS.
Q: – List the components required to build Amazon VPC?
Ans:- Subnet, Internet Gateway, NAT Gateway, HW VPN Connection, Virtual Private Gateway, Customer Gateway, Router, Peering Connection, VPC Endpoint for S3, Egress-only Internet Gateway.
Q: – Mention what are the key components of AWS are?
Ans:- The key components of AWS are
- Route 53:A DNS web service
- Simple E-mail Service:It allows sending e-mail using RESTFUL API call or via regular SMTP
- Identity and Access Management:It provides enhanced security and identity management for your AWS account
- Simple Storage Device or (S3):It is a storage device and the most widely used AWS service
- Elastic Compute Cloud (EC2): It provides on-demand computing resources for hosting applications. It is handy in case of unpredictable workloads
- Elastic Block Store (EBS):It offers persistent storage volumes that attach to EC2 to allow you to persist data past the lifespan of a single Amazon EC2 instance
- CloudWatch: To monitor AWS resources, It allows administrators to view and collect key Also, one can set a notification alarm in case of trouble.
OR
Q: –Name the basic components of Amazon Web Services?
Ans:- Amazon Web Services or AWS consists of 4 main components that are as listed below:
- Amazon S3: This component has been designed to enable one to retrieve information which has been occupied in creating the cloud structural design and also retrieve the produced information as a consequence of the specified key.
- Amazon EC2 instance: This component has been designed in order to run automatic parallelization and also achieve job scheduling. This instance is immensely helpful in running a large distributed system on the Hadoop Cluster.
- Amazon SimpleDB: This component helps in the storage of the transitional positional log and also run the errands when they are executed by the client or the consumer.
- Amazon SQS: This component has been mainly designed to act as a mediator between different controllers. This is an additional cushioning for the managers at Amazon.
OR
Q: – List out the main components of AWS.
Ans:- Similar to other Cloud Services in the industry, AWS too has been designed in a structured manner and has several key components. Mentioned below is the list of the same:
- Amazon Route 53: This is a DNS (Domain Name Service) web service.
- Easy Email Service: This service allows customers and clients to address email utilization through normal SMTP or RESTFUL API.
- Access Management and Identity: This has been designed in order to provide heightened identity control and protection for a client’s AWS account.
- S3 or Simple Storage Device: It is a very well-known utility among all the AWS Services and is mainly used in warehouse equipment.
- EC2 or Elastic Compute Cloud: This is a utility designed to manage variable workloads and gives clients the ability to afford on-demand computing sources for hosting.
- EBS or Elastic Block Store: This particular utility is used to expand beyond EC2 and is designed to connect EC2 to enable the lifespan of data beyond the capacities of EC2.
- Cloud Watch: This is mainly a crisis management utility and is designed to help managers inspect and obtain additional resources in the light of a crisis.
Q: – List the Features of Amazon cloud search?
Ans:- The Amazon cloud search features:
- Range searches
- Prefix Searches
- Boolean Searches
- Entire text search with language specific text processing
- Highlighting
- AutoComplete advice
- Faceting term boosting
Q: – What is auto-scaling?
Ans:- Auto-scaling is a feature of AWS which allows you to configure and automatically provision and spin-up new instances without the need for your intervention.
Q: – Define auto-scaling ?
Ans:- Auto- scaling is one of the remarkable features of AWS where it permits you to arrange and robotically stipulation and spin up fresh examples without the requirement for your involvement. This can be achieved by setting brinks and metrics to watch. If those entrances are overcome, a fresh example of your selection will be configured, spun up and copied into the weight planner collection.
OR
It is one of the outstanding features of AWS, which permits the arrangement and stipulation robotically and also the spin up fresh example without the user’s involvement.This feature can be achieved by setting metrics and brinks to the watch.
A fresh example of the user’s selection is configured, spinup and copied to the weight planner collection if we overcome all those entrances.
Q: – What do you mean by classic link?
Ans:- The Amazon virtual private cloud classic link will permit EC2 instances in the EC2 classic platform. This occurs so that it can communicate with the instances that are present in the virtual private cloud. The communication occurs with the help of private IP addresses. In order to use a classic link it is important that you enable it to for virtual private cloud in your account. Then you will need to associate a security group with an instance in the EC2 classic. This security group is from the VPC for which you enabled the classic link in your account. Each and every rule that is there for the VPC security group is applicable for the communications between the instances in EC2 classic and those instances in the VPC.
Q: –Explain what is Amazon S3 ?
Ans:-S3 stands for Simple Storage Service. You can use S3 interface to store and retrieve any amount of data, at any time and from anywhere on the web. For S3, the payment model is “pay as you go.”
OR
S3 stands for Simple Storage Service. It is a storage service that provides an interface that you can use to store any amount of data, at any time, from anywhere in the world. With S3 you pay only for what you use and the payment model is pay-as-you-go.
OR
Amazon S3 (Simple Storage Service) is an object storage with a simple web service interface to store and retrieve any amount of data from anywhere on the web.
OR
S3 stands for Simple Storage Service, which is an interface to store and retrieve any amount of data from anywhere and at any time on the web.”Pay as you go” is the payment model for S3.
Q: – What are the pricing models for EC2 instances?
Ans:- The different pricing model for EC2 instances are as below,
- On-demand
- Reserved
- Spot
- Scheduled
- Dedicated
Q: – What are key-pairs?
Ans:- Key-pairs are secure login information for your instances/virtual machines. To connect to the instances we use key-pairs that contain a public-key and private-key.
Q: – What is the way to secure data for carrying in the cloud?
Ans:- One thing must be ensured that no one should seize the information in the cloud while data is moving from point one to another and also there should not be any leakage with the security key from several storerooms in the cloud. Segregation of information from additional companies’ information and then encrypting it by means of approved methods is one of the options.
Amazon Web Services offers you a secure way of carrying data in the cloud
Q: – Name the several layers of Cloud Computing.
Ans:- Here is the list of layers of the cloud computing
PaaS – Platform as a Service
IaaS – Infrastructure as a Service
SaaS – Software as a Service
Q: – What type of performance can you expect from Elastic Block Storage? How do you back it up and enhance the performance ?
Ans:-Performance of an elastic block storage varies i.e. it can go above the SLA performance level and after that drop below it. SLA provides an average disk I/O rate which can at times frustrate performance experts who yearn for reliable and consistent disk throughput on a server. Virtual AWS instances do not behave this way. One can backup EBS volumes through a graphical user interface like elasticfox or use the snapshot facility through an API call. Also, the performance can be improved by using Linux software raid and striping across four volumes.
Q: – Imagine that you have an AWS application that requires 24x7 availability and can be down only for a maximum of 15 minutes. How will you ensure that the database hosted on your EBS volume is backed up?
Ans:- Automated backup are the key processes here as they work in the background without requiring any manual intervention. Whenever there is a need to back up the data, AWS API and AWS CLI play a vital role in automating the process through scripts. The best way is to prepare for a timely backup of EBS of the EC2 instance. The EBS snapshot should be stored on Amazon S3 and can be used for recovery of the database instance in case of any failure or downtime.
Q: – Difference between Security Groups and ACLs in a VPC?
Ans:- A Security Group defines which traffic is allowed TO or FROM EC2 instance. Whereas ACL, controls at the SUBNET level, scrutinize the traffic TO or FROM a Subnet.
Q: – What does an AMI include?
Ans:- An AMI includes the following things
A template for the root volume for the instance
Launch permissions decide which AWS accounts can avail the AMI to launch instances
A block device mapping that determines the volumes to attach to the instance when it is launched
Q: – What is Amazon Machine Image (AMI) ?
Ans:- AMI stands for Amazon Machine Image. It’s a template that provides the information (an operating system, an application server, and applications) required to launch an instance, which is a copy of the AMI running as a virtual server in the cloud. You can launch instances from as many different AMIs as you need.
OR
Amazon Machine Image is the full form of AMI.It is actually a template that provides the information of the operating system, server, applications etc., required to launch an instance that is the replica of the AMI running in the cloud as a virtual server.
An instance can be launched from as many different AMIs as per the requirement.
OR
A Machine Image on Amazon (AMI) contains a software configuration information like OS information, app server, and app information. We can even launch multiple instances of an AMI.
Q: – What is an AMI?
Ans:- AMI (Amazon Machine Image) is a snapshot of the root filesystem.
Q: – An organization wants to deploy a two-tier web applications on AWS. The application requires complex query processing and table joins. However, the company has limited resources and requires high availability. Which is the best configuration that company can opt for based on the requirements ?
Ans:- DynamoDB deals with core problems of database scalability, management, reliability, and performance but does not have the functionalities of a RDBMS. DynamoDB does not render support for complex joins or query processing or complex transactions. You can run a relational engine on Amazon RDS or EC2 for this kind of a functionality.
Q: – If you have half of the workload on public cloud while the other half is on local storage, what kind of architecture will you use for this ?
Ans:- Hybrid Cloud Architecture
Q: – Is it possible to cast-off S3 with EC2 instances ? If yes, how ?
Ans:- It is possible to cast-off S3 with EC2 instances using root approaches backed by native occurrence storage.
Q: – How many EC2 instances can be used in a VPC ?
Ans:- There is a limit of running up to a total of 20 on-demand instances across the instance family , you can purchase 20 reserved instances and request spot instances as per your dynamic spot limit region.